My homelab's first failing hard drive
It was a sunny weekday afternoon and I was at my desk working when I received a Pushover notification on my phone. I exclusively use Pushover for homelab alerting, it makes it quick and easy to discern any homelab notifications from a myriad of others. The notification was a dreaded warning from Scrutiny, a disk was failing.
“Scrutiny SMART error detected on device sdb” the notification read. I quickly loaded up Scrutiny in my browser and there it was, my first disk reported as “Failed.”
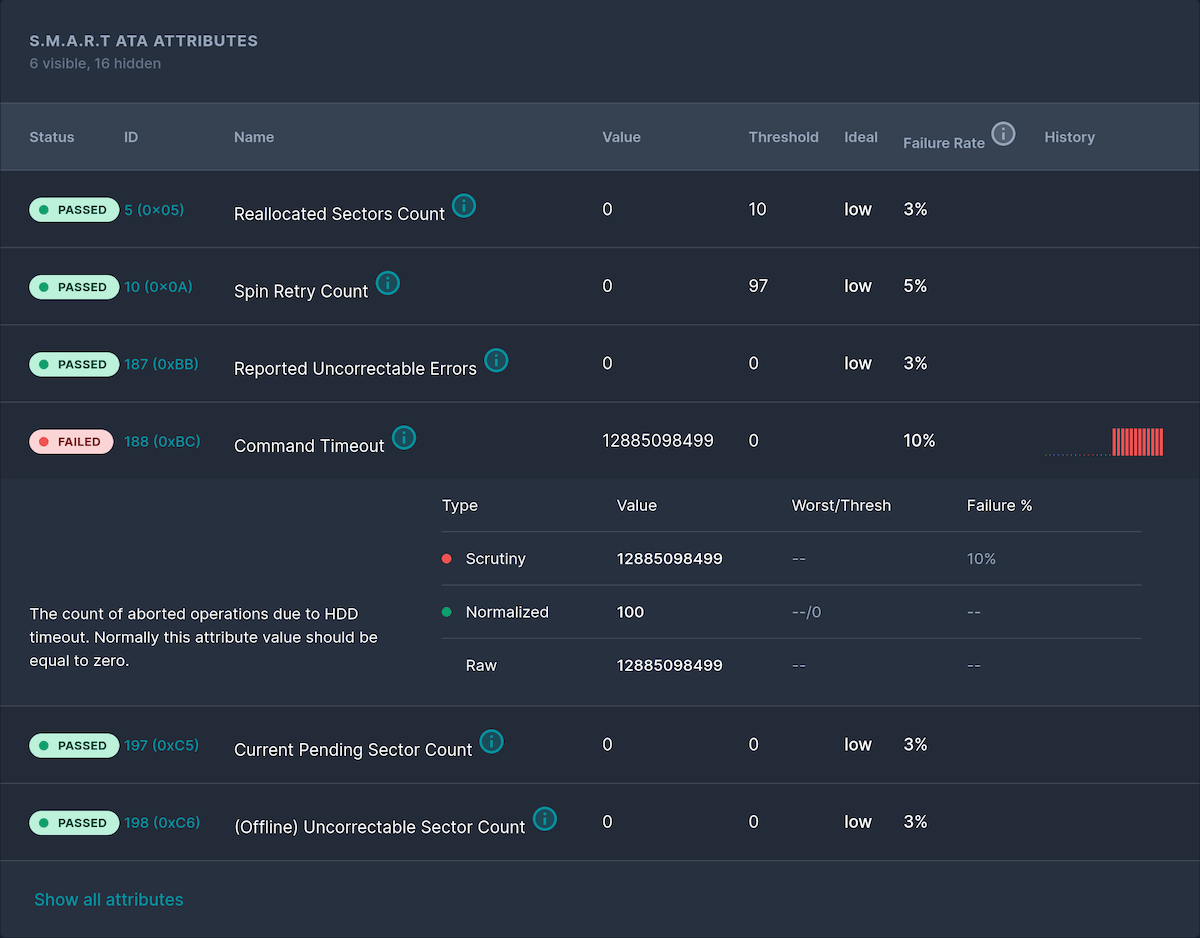
Clicking into the disk to inspect the issue, I see the “Command Timeout” was failing. It was a big number too, and as of writing this it is sat at 12885098499. However, from some quick searching online, it would seem this is a raw value and not the actual number of aborted operations. The real number is 3 out of 196,611 operations.
There is a good write up about raw SMART values here by DiskTuna which goes into more depth. But to summarize, the value needs to be converted to hexadecimal, which can then be split up and interpreted using documentation from the vendor. Or you can just use this tool from DiskTuna like I did.
Interestingly, when running a SMART check in Unraid, the disk passes with flying colours, no issues found, so nothing to worry about right?
Well this number has increased from 0 to 3 in the space of 2 months. Additionally I have a second disk which is the same make and model, purchased at the same time, and has always been used alongside the failing disk. This second disk has a command timeout value of 0 and is perfectly healthy.
Furthermore, Scrutiny uses the data from Backblaze, a large cloud storage provider who publish in-depth reports on their disk failures. Using this data Scrutiny can help predict if a disk is likely to fail, something that Unraid’s SMART check does not do. Scrutiny have more information about this in their documentation.
With that in mind, I felt a little uneasy just ignoring the issue. I of course back up my data and make use of a parity drive in Unraid in case of a disk failure. But to further protect my data I decided to add a second larger parity drive to the array, once the failing disk finally kicks the bucket, I will replace it with a new higher capacity disk.
The disk is also still within warranty, being about a year and a half old. However I’m reluctant to RMA the disk until it actually fails after reading their RMA terms:
Product that you return to Seagate will not be returned to you if it passes the Seagate warranty validation process. You agree that title to such returned Product will be transferred to Seagate.
…
Seagate will return the Product to you only if you make a written request in accordance with the notification we send to you. In order to request the return of a Product, you must provide the information requested in the notice within fifteen (15) days of the date of the notice for US customers and within thirty (30) days of the date of the notice for non-US customers. Seagate reserves the right to charge you a processing and inspection fee for Product or materials returned that are not in compliance with these Terms and the Seagate Return Policy.
In the meantime, the disk spins on.